引言
有两个多月没更新了,这阵子主要一是工作忙,二是研究了一下数据中台,对其中的建模理论和数据流转有了较为深入的理解,于是打算自己做一套可以实际落地的产品出来,但实现起来真的不简单,之前做的数睿通主要是数据治理,也是不错的项目,这次准备做个大而全的,引入一些最新的技术,目前我自己单枪匹马做了大概有一两周的时间,数据集成模块的数据库管理和数据接入的功能基本算是完成了。数据接入部分其实可以作为 ETL 使用,下面的功能模块说明里会有具体的介绍,想要源码和相关资料的朋友请见文末。
前端是硬伤,作为后端的我写起来吃力,于是拉了几个前端大佬,还拉了几个有大数据开发经验的好朋友,还有一个玩的好的项目经理,这样算是成立了一个小团队,希望真的可以如愿,把事情做成!下面一起看下系统的功能模块,相关的概念,还有我这两周挤时间做出来的成果吧。
项目介绍
系统还是起名为数睿通,之前是1.0,这次2.0,是采用 Vue3,Ts,Spring Cloud Alibaba、SpringSecurity、Spring Cloud Gateway、SpringBoot、Nacos、Redis、Mybatis-Plus,tidb,flink,neo4j 等最新技术,开发的数据中台,包含数据集成,数据开发,数据治理,数据资产,数据服务,数据集市六大模块,致力于解决数据孤岛问题,实现数据统一口径标准,自定义数据开发任务,帮助企业,政府等解决数据问题。
功能模块说明
数据集成:
数据库管理 — 管理用户添加的数据源,支持 MYSQL/ORACLE/SQLSERVER/POSTGRESQL/GREENPLUM/MARIADB/DB2/DM/OSCAR/KINGBASE8/OSCAR/GBASE8A/HIVE/SQLITE3/SYBASE,支持库表查询,测试连接等(已完成)
文件管理 — 管理用户上传的文件数据
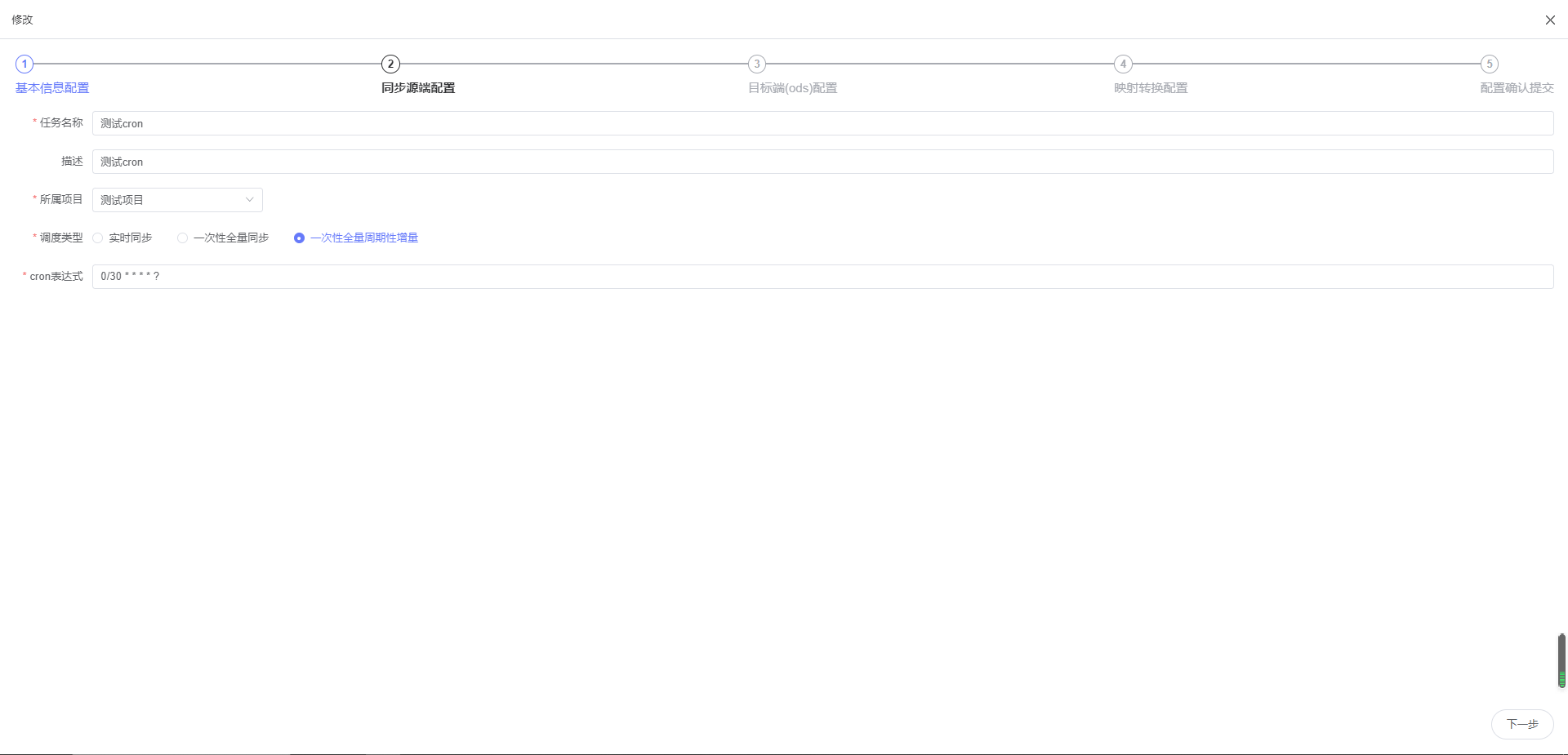
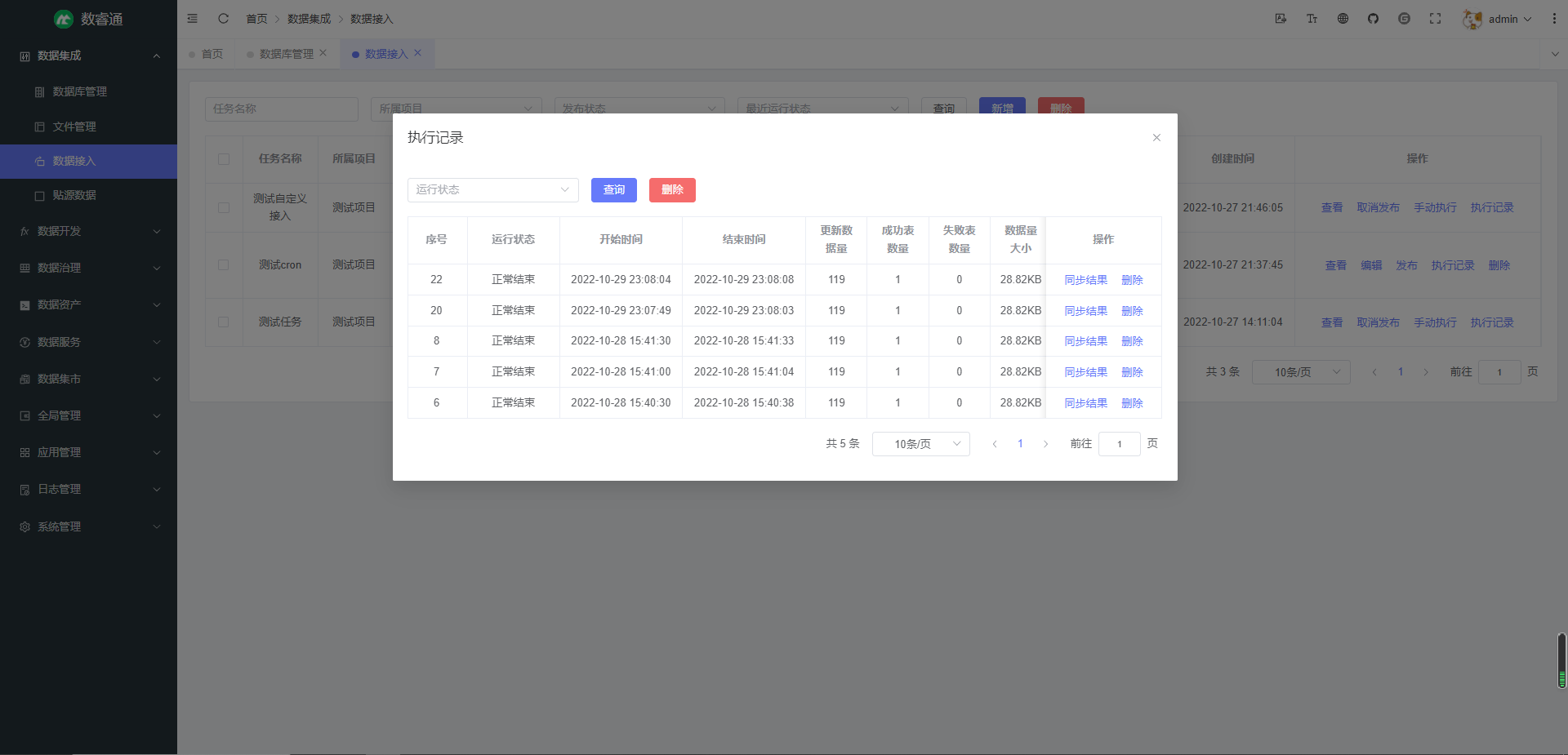
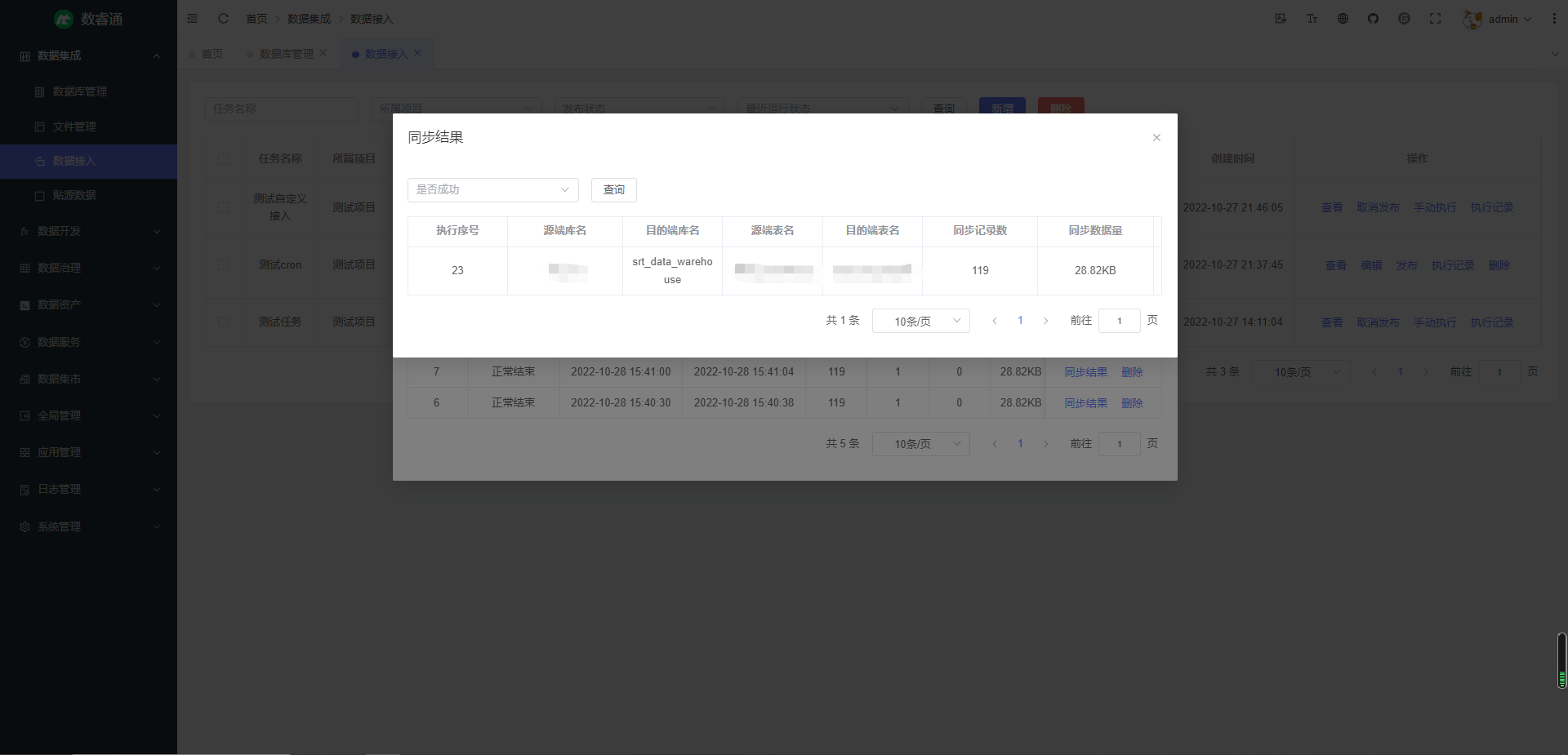
数据接入 — 接入外部数据源的数据到中台 ODS 层,也可自定义接入目的端数据源,支持一次性全量同步和周期性增量同步;可自定义表名,字段名的映射规则,支持正则表达式匹配;支持查看执行记录及详细执行结果,可查看同步的数据量,数据大小,成功表数量,失败表数量,成功信息,失败信息,也可查看具体每张表同步的数据量,数据大小,错误信息等,帮助用户全面掌握数据接入的执行情况(已完成)
贴源数据 — 查看接入到ods层的数据表和数据,可查看每张表的同步记录
数据开发:
维度表 — 中台 DIM 层,用户可以根据业务自行创建维度表,定义结构,导入数据,也可以自定义装载sql,维度是由明细表抽取通用的,描述一类对象的字段而得,如日期维度,类型维度等,后续可以根据维度结合指标对数据进行聚合操作
明细表 — 中台 DWD 层通过企业的业务活动事件构建数据模型。基于具体业务事件的特点,构建最细粒度的明细数据事实表,明细表通常由维度字段和度量值组成,也可冗余简单的维度字段,通常明细表和维度表的构建分为星型模型和雪花模型,但雪花模型严格遵守建模规范,导致维度表中可能还会关联其他的维度(类比数据库三范式,很多情况下我们不会根据范式建表),导致统计分析成本大大提高,所以一般采用星型模型,即一个明细表关联多个维度表,可自定义结构,导入数据,也可自定义装载sql
汇总表 — 基于指标和在指标中定义关联的维度对明细表进行聚合处理,得到基于指标处理之后的数据,创建发布之后用户可以选择是否生成数据生产任务,生成后的数据可用于 ADS 层,直接或进一步汇总后对外提供服务
自主建表 — 用户根据自身需求灵活建表,可用于定义 ADS 层的数据结构,可自定义装载 sql
数据主题 — 自定义主题,对主题进行分类管理,每个主题下面可以创建指标,指标分为原子指标(例如求和,求平均等),派生指标(在原子指标基础上加入统计维度概念,同时可以自定义条件限制,时间范围等),衍生指标(多个派生指标计算得出,如比例),指标创建后可用于后续的数据开发工作
数据生产 — 分为自动生成的任务和自定义的生产任务,用户可以直接编写 flink sql,也可采用流程配置的方式配置生产任务
数据展示 — 展示数据生产的成果
数据治理:
元模型 — 描述元数据的元数据,主要定义了元数据的属性,通常元模型都是系统内置的,如表元模型,字段元模型等
元数据采集 — 根据定义的元模型对元数据进行采集,通常是每一种元模型有自己内置的采集逻辑,可以设置采集周期等
元数据管理 — 对采集的元数据进行查看和管理
数据血缘 — 通过数据接入,数据生产流程之间的关系自动构建数据血缘关系图,追溯数据流向,使用 neo4j 图数据库构建
数据资产:
资源管理 — 自定义资源目录,在每个目录下自定义资源,挂在数据库,api等
资产总览 — 对中台资源做一个总的统计概览
数据服务:
API 管理 — 用户自定义API,对外提供服务
数据可视化 — 支持对数据进行图表,大屏等的可视化
数据集市:
资源目录 — 中台资源目录以及目录下资源的查看,可对资源进行申请操作
API 目录 — 中台 API 目录以及目录下 API 的查看,可对 API 进行申请
我的申请 — 可以查看自己的申请记录,审批结果
服务审批 — 管理员对其他角色的申请做出审批,若审批通过,申请人便可以收到审批通过的消息,使用自己申请的服务资源
全局管理:
数据项目管理 — 中台项目的管理,每个项目下可以关联用户,用户只能查看自己关联的项目下的数据,所有的模块数据都会有所属项目 (已完成)
数仓分层展示 — 对中台数仓的分成做展示说明 (已完成)
应用管理:
短信平台 — 集成短信平台,支持阿里,腾讯等常用的短信平台 (已完成)
短信日志 — 调用短信所产生的日志 (已完成)
日志管理:
登录日志 — 系统登录产生的日志 (已完成)
系统管理:
用户管理 — 对系统用户进行管理 (已完成)
菜单管理 — 对系统菜单进行管理,用于实现动态菜单 (已完成)
定时任务 — 可自定义定时任务,调度执行 (已完成)
数据字典 — 系统的字典数据 (已完成)
机构管理 — 机构数据,若各模块中的数据有所属机构概念,可用于数据权限管理 (已完成)
岗位管理 — 岗位的管理 (已完成)
角色管理 — 角色管理,可以为每个角色自定义菜单查看权限以及机构级的数据权限 (已完成)
附件管理 — 系统附件管理,可以上传下载 (已完成)
系统数仓架构
该系统主要基于 Flink + TiDB 构建准实时数仓,进行数据同步,流转,计算和分析处理,下面是 Flink 和 TiDB 的相关说明:
Flink 是一个低延迟、高吞吐、流批统一的大数据计算引擎,被普遍用于实时性场景下的计算统计和分析。
在集成了 TiFlash 之后,TiDB 已经成为了真正的 HTAP(在线事务处理 OLTP + 在线分析处理 OLAP)数据库。换句话说,在实时数仓架构中,TiDB 既可以作为数据源的业务数据库,进行业务查询的处理;又可以作为实时 OLAP 引擎,进行分析型场景的计算。
结合了 Flink 与 TiDB 两者的特性,Flink+ TiDB 的方案的优势也体现了出来:首先是速度有保障,两者都可以通过水平扩展节点来增加算力;其次,学习和配置成本相对较低,因为 TiDB 兼容 MySQL 5.7 协议,而最新版本的 Flink 也可以完全通过 Flink SQL 和强大的连接器(connector)来编写提交任务,节省了用户的学习成本。
相比传统数仓(Hadoop + Hive ),除了进行常规的批量计算,还可以满足实时计算的需求。
数仓整体架构图如下:
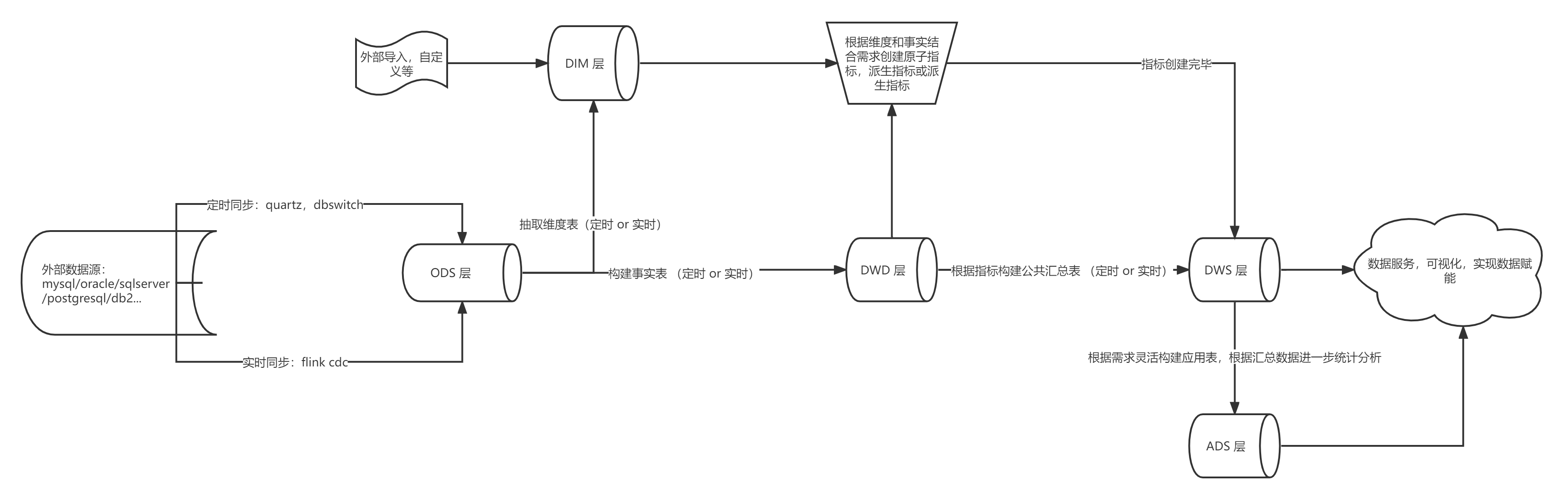
关于数仓为什么要分层:分层可以有助于数据的管理,同时每次取数只需要获取统计分析过的成品就可以,不需要从源头数据反复计算,避免了计算资源的浪费,通常源头数据量较大,并且中间的处理逻辑较为复杂,所以采用建模分层的方式解决。
系统核心技术栈
前台:
- vue3
- vite
- typeScript
- element-plus
- pinia
- 。。。
后台:
- Spring Cloud Alibaba
- SpringSecurity
- Spring Cloud Gateway
- SpringBoot
- Nacos
- Redis
- Mybatis-Plus
- mysql8.0
- tidb
- flink
- flink cdc
- flink sql
- neo4j
- 。。。
系统运行方式
下载Nacos
需要从GitHub下载Nacos,下载地址:https://github.com/alibaba/nacos/releases
下载2.1.1版本,因为本项目使用的是Nacos 2.1.1,如果版本号对应不上,后面项目启动会出错。
nacos数据库
注意:Nacos 目前只支持MySQL数据库,请安装MySQL8.0版本,以免出现其他错误。
新建数据库nacos_config,并运行【conf/nacos-mysql.sql】文件,初始化数据库即可。
修改Nacos的配置文件
需要在【conf/application.properties】文件末尾,新增如下配置:
# 填自己的ip地址,本地填127.0.0.1就行
nacos.inetutils.ip-address=127.0.0.1
spring.datasource.platform=mysql
db.num=1
#填自己的数据库连接和密码
db.url.0=jdbc:mysql://127.0.0.1:3306/nacos_config?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true&useUnicode=true&useSSL=false&serverTimezone=UTC
db.user.0=root
db.password.0=root启动Nacos
Windows:
startup.cmd -m standalone
Linux:
sh startup.sh -m standalone
# 集群启动可关注公众号 螺旋编程极客 查看访问Nacos管理界面(http://localhost:8848/nacos) ,初始用户名nacos,密码nacos,登录之后,如下所示:
创建系统数据库
创建 srt_cloud 数据库,数据库编码为utf8mb4
执行db/srt_cloud.sql文件,初始化数据库脚本
创建 srt_data_warehouse数据库(数仓使用,应该搭建tidb(官网有教程),测试可以直接使用mysql数据库)
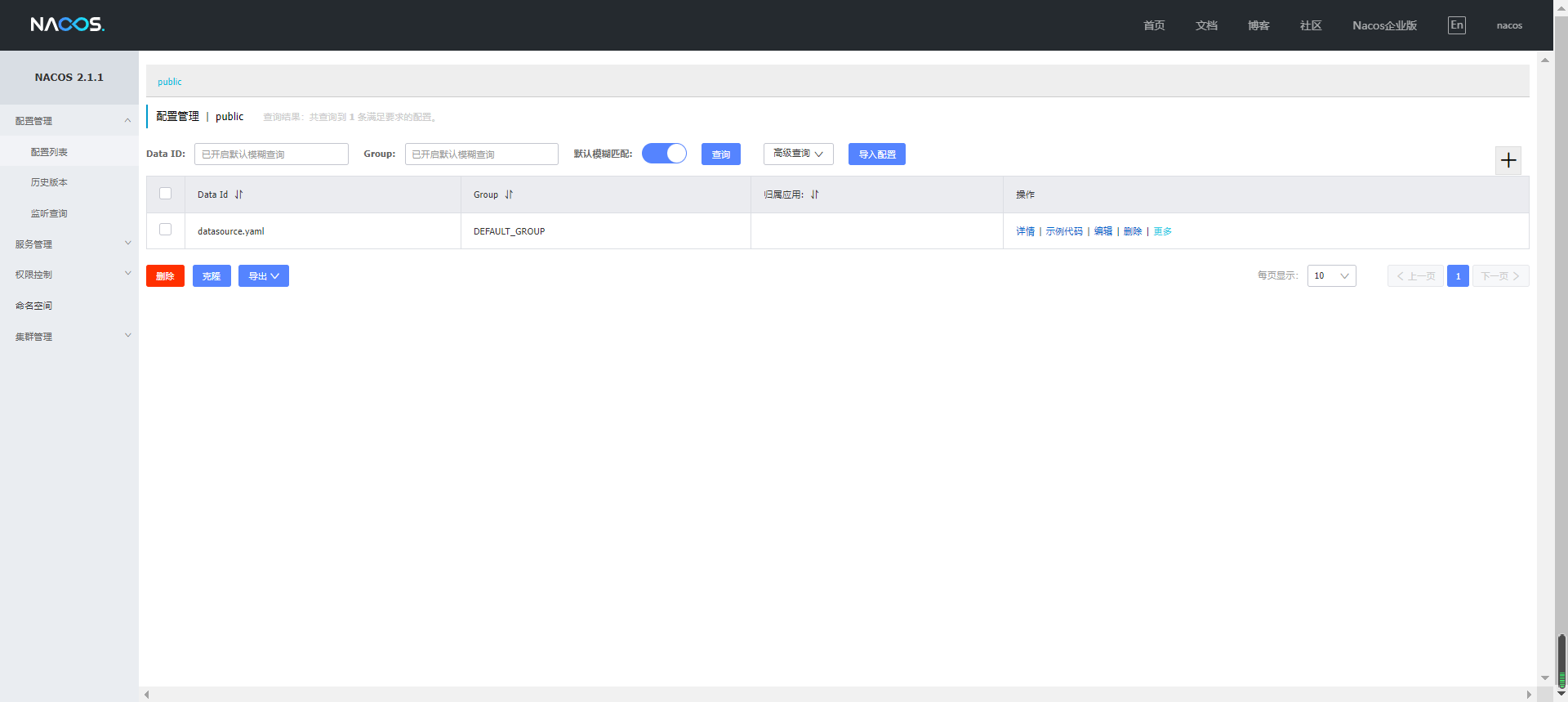
导入Nacos配置文件
导入Nacos配置文件,配置文件在项目里,文件名为:【deploy/nacos_config.zip】,如下所示:
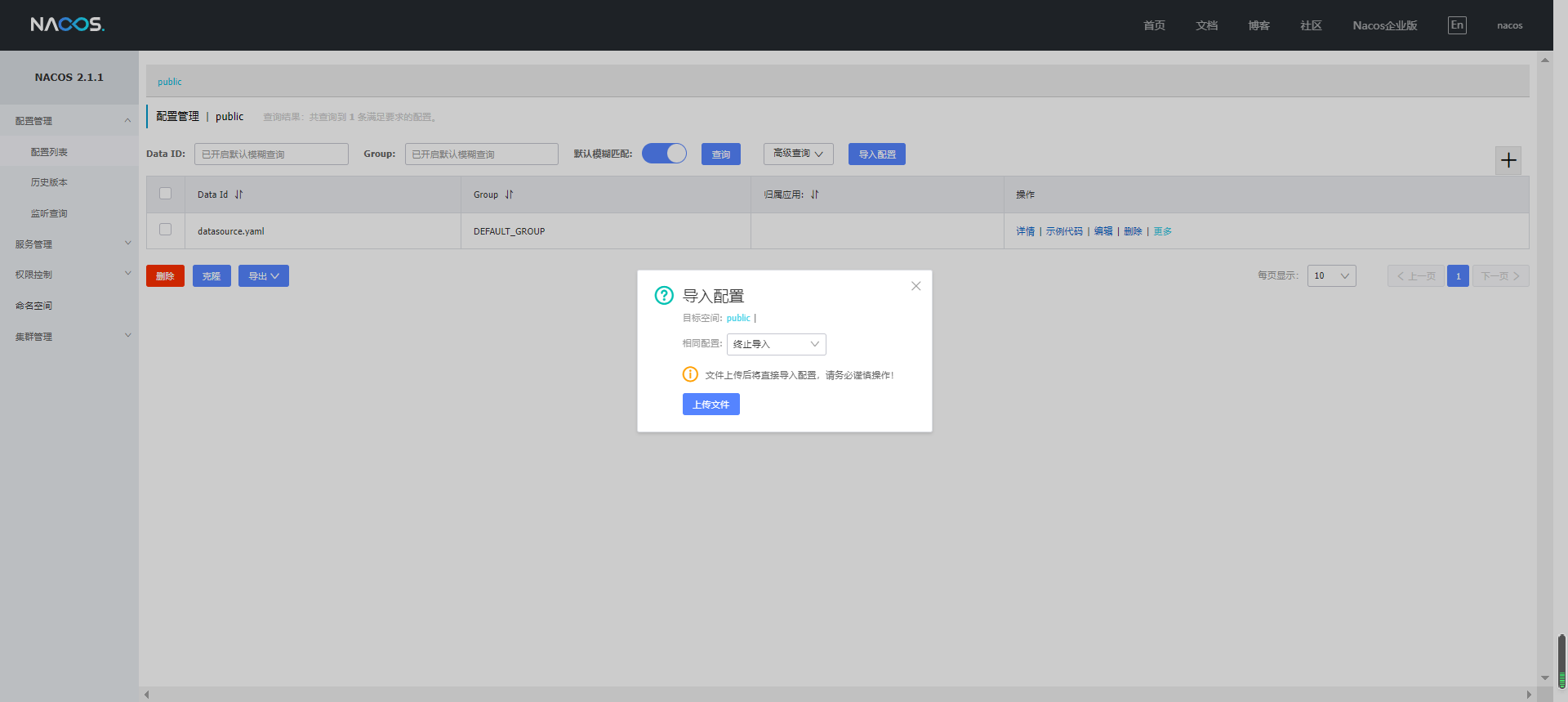
导入配置文件后,还需要在Nacos里,修改datasource.yaml,如:Redis、MySQL信息等。
启动后端
把系统导入 idea,导入完 maven 依赖之后,依次启动:
启动 srt-cloud-gateway
运行 GatewayApplication.java
启动 srt-cloud-system
运行 SystemApplication.java
启动 srt-cloud-data
运行 SrtDataApplication.java
启动 srt-cloud-quartz
运行 QuartzApplication.java
启动 srt-cloud-message
运行 MessageApplication.java
启动前端
安装版本号为16.15.0的nodejs,如果已经安装了,请先卸载,推荐使用 nvm 安装 node.js,方便切换不同版本
- 需要先把本地安装的
nodejs卸载,然后再下载nvm,地址:
https://github.com/coreybutler/nvm-windows/releases - 一般情况,找到最新版本,然后下载
nvm-setup.exe文件就可以了,下载后,我们双击安装即可。 - 我们使用
PowerShell打开命令行,这里需要注意下,要使用管理员身份打开PowerShell - 命令
nvm version,可以查看版本号 - 命令
nvm ls available查看nodejs可用的版本 - 命令
nvm install 16.15.0,可以安装版本号为16.15.0的nodejs - 命令
nvm list,可以查看已安装的版本号 - 命令
nvm use 16.15.0,可以切换到版本号为16.15.0的nodejs,现在就可以通过命令node -v查看当前的nodejs版本号 - 命令
nvm uninstall 16.15.0,可以卸载版本号为16.15.0的nodejs
用 vscode 或 hbuildx 打开 srt-cloud-web
安装依赖:
npm install运行项目:
npm run dev打包项目
npm run build系统运行展示
目前只完成了数据集成模块的数据库管理,数据接入,全局管理模块的全局项目管理和数仓分层展示以及系统管理的全部功能,其他功能模块之后会陆续实现完成,相信在不久的将来就能与大家见面!
登录:
首页:
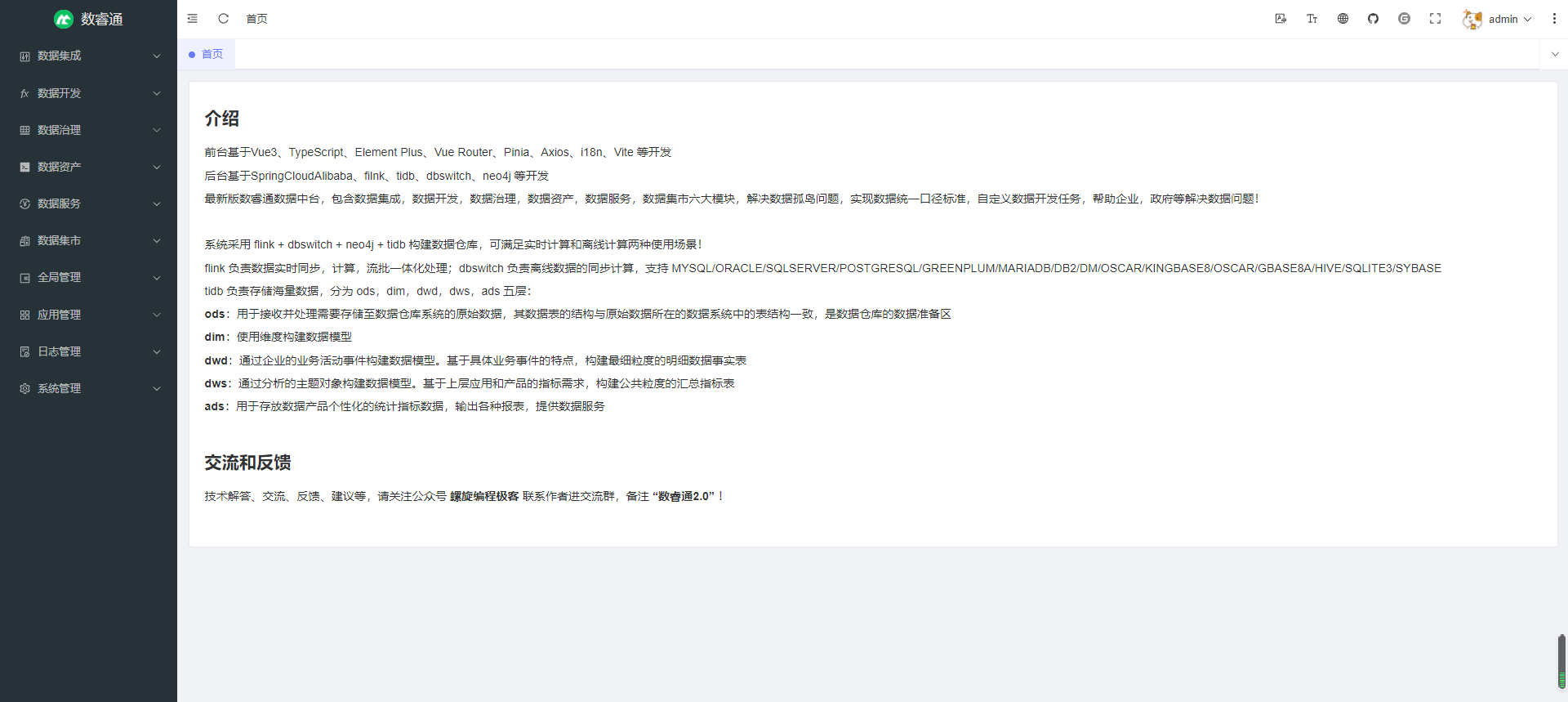
数据库管理:
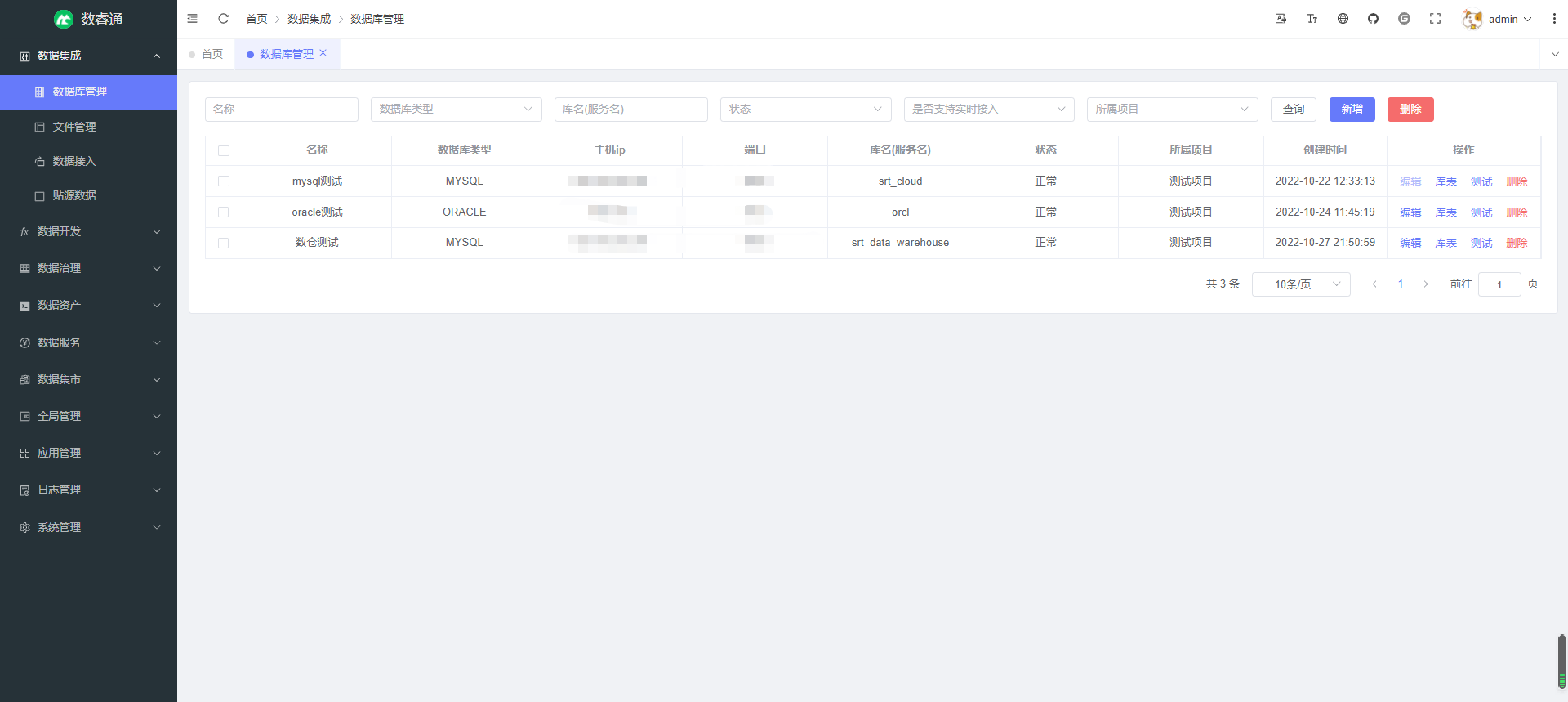
修改数据库:
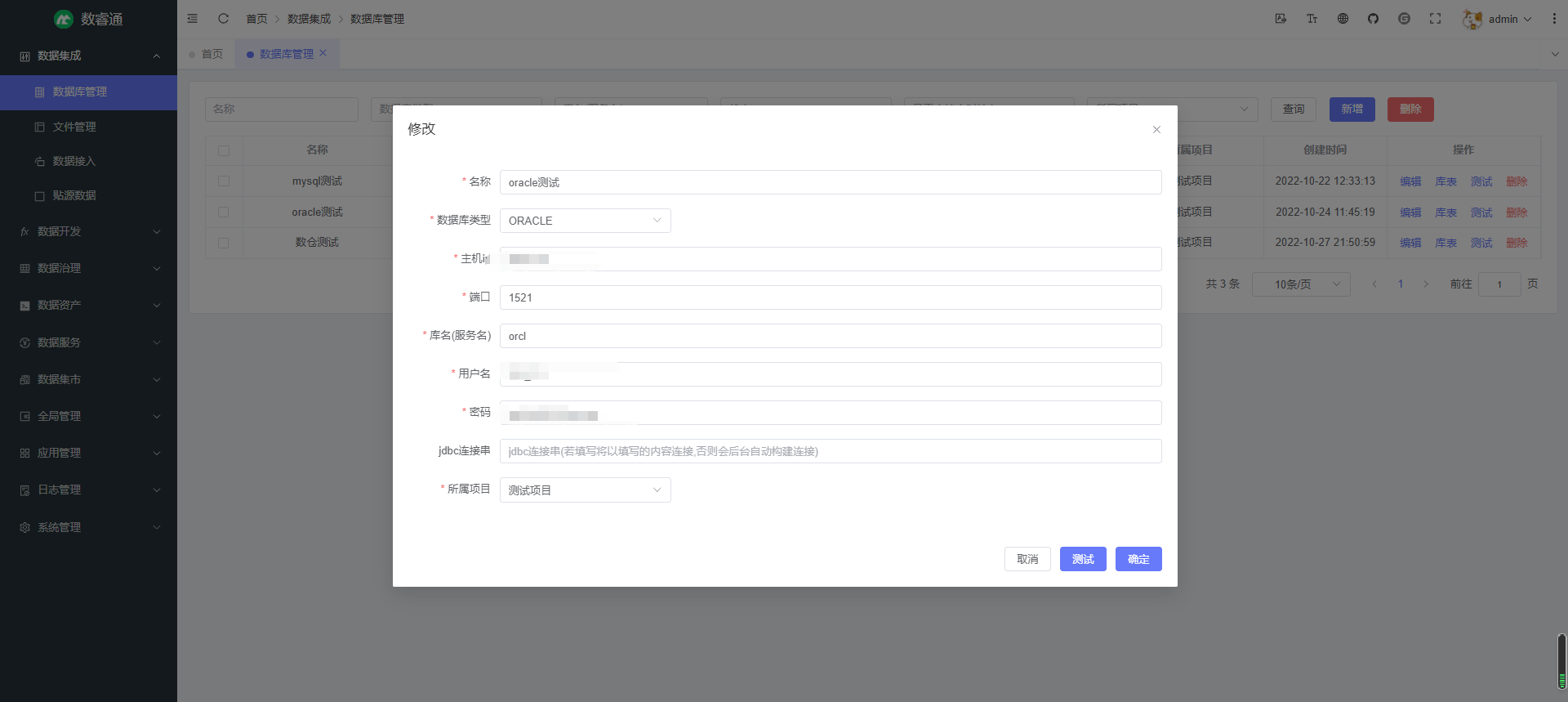
数据接入:
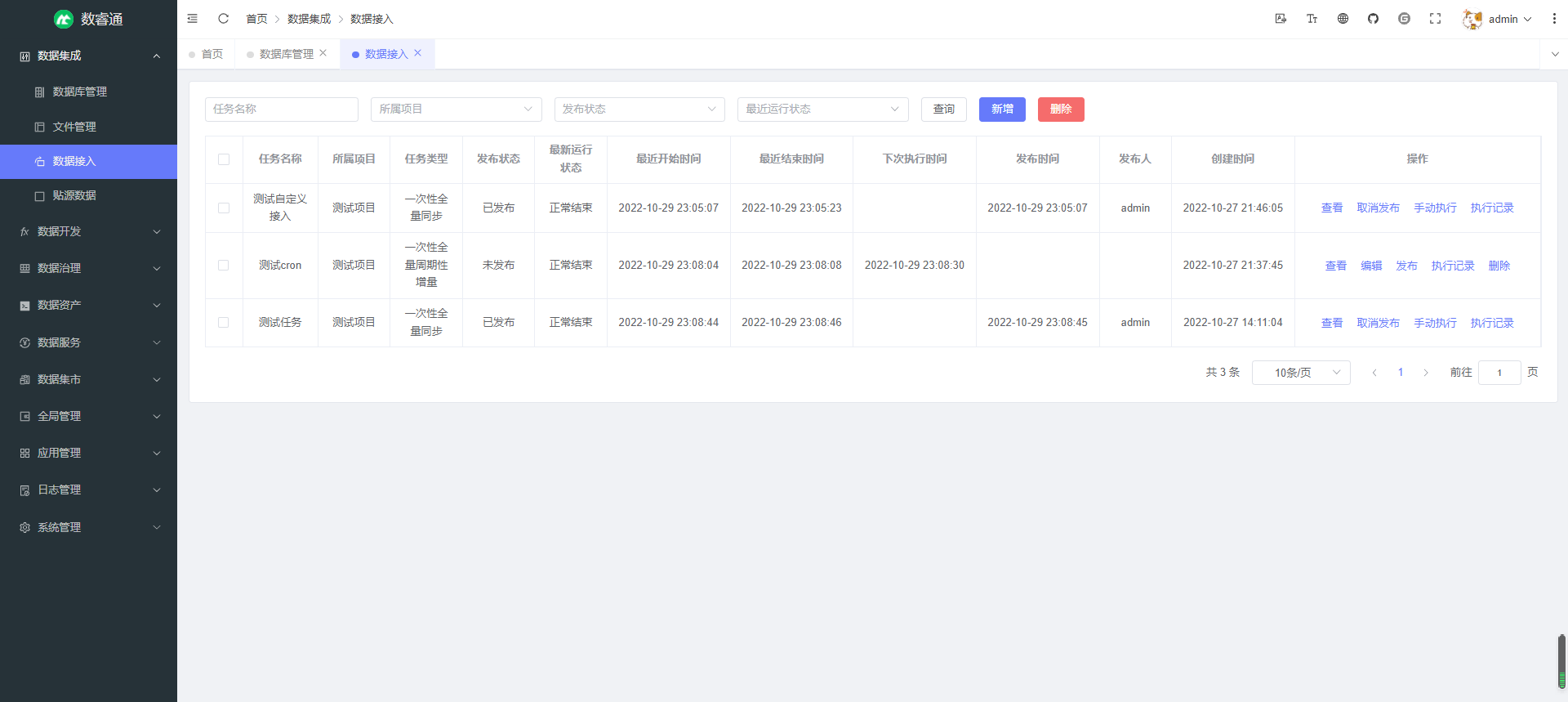
接入查看:
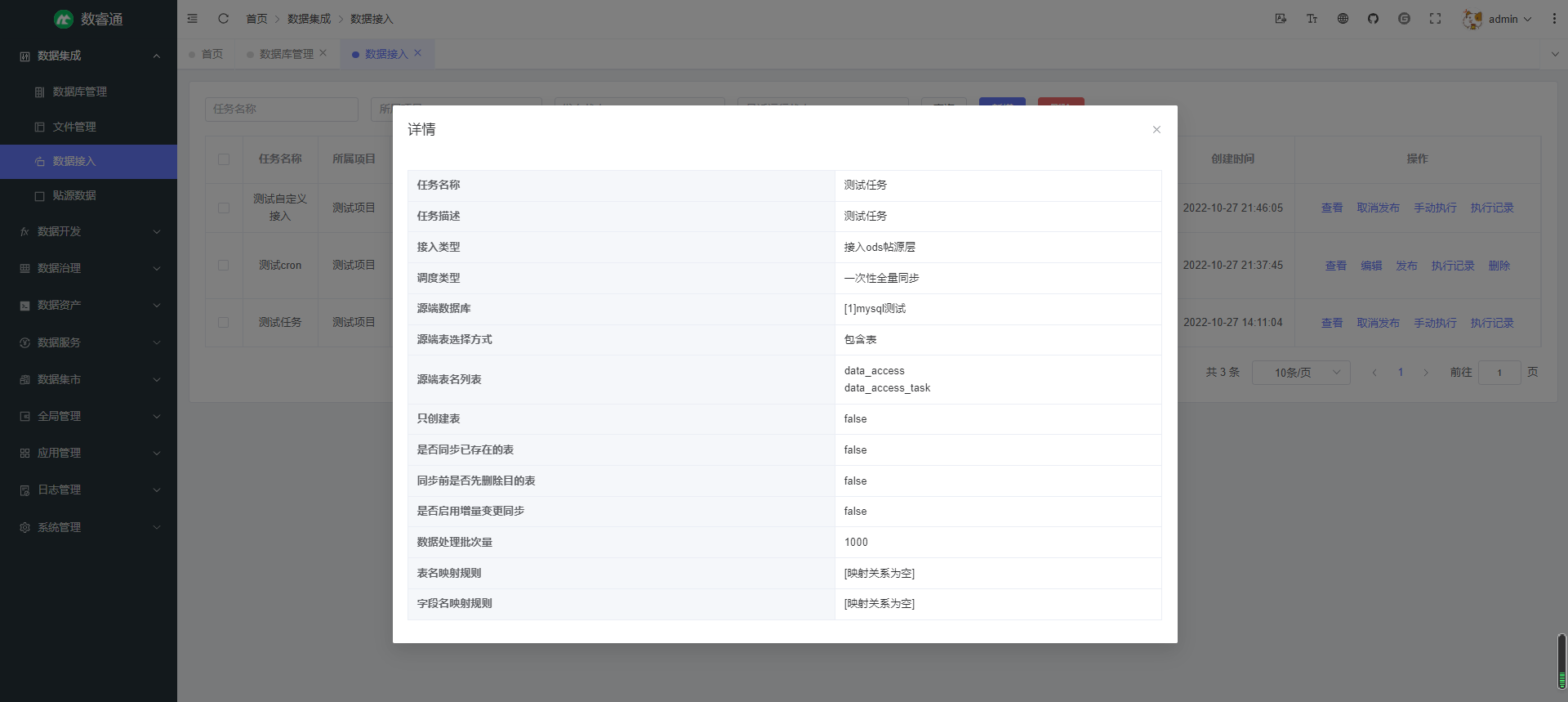
接入编辑:
执行记录:
同步结果:
结语
这就是数睿通的最新进度了,等几位小伙伴们真正投入开发之后进度应该会加快,界面也会变的酷炫一些!数据接入模块目前作为 ETL 是可以实际落地使用的,在数据库管理添加完数据库,就可以添加数据接入任务,自定义源端和目的端,配置同步策略(是否同步索引,大小写转化等),表名和字段名映射规则,实现数据同步,如果有数据同步需求的朋友可以一试,用于个人学习也是没有问题的,前后端技术都是最新的,肯定会有所收获!
当然代码不是白嫖的,用爱发电实在是太累了,这次是真的准备把东西搞出来,我对此也有信心,现在有了一套完整的方法论和实现思路,剩下的就是动手加紧做,当然做的时候肯定会遇到各种问题,但一定可以克服,有志者,事竟成。
想要源码的朋友可以关注公众号 螺旋编程极客 获取
、

作者加下我!